《字符串搜索算法》

《算法与数据结构:字符串搜索算法》
引言
字符串匹配是计算机科学中一个基础而重要的问题,它涉及在一个文本字符串中寻找一个子字符串的过程。这一问题在许多领域都有广泛的应用,包括文本编辑、生物信息学、数据检索等。在众多解决字符串匹配问题的算法中,KMP(Knuth-Morris-Pratt)算法因其高效的匹配过程而著称。不同于传统的朴素匹配方法,KMP 算法利用已匹配的部分信息避免从头开始匹配,大大提高了搜索效率。本文旨在为初学者提供一个关于 KMP 算法的入门指南,介绍其基本概念、工作原理及应用场景。
字符串匹配基础
字符串匹配是指在一个较长的文本字符串中查找一个指定的子字符串的过程。这个问题看似简单,实则是许多计算机应用的核心部分,例如,在一个大型文档中查找特定单词,或者在网页搜索中定位关键词。字符串匹配的效率直接影响到这些应用的性能和用户体验。
朴素字符串匹配算法
最直观的字符串匹配方法是朴素字符串匹配算法。该算法从文本的第一个字符开始,逐个字符地将子字符串与文本中的连续字符段进行比较。如果所有字符都匹配,则认为找到了一个匹配位置;如果某个字符不匹配,则算法将子字符串向前移动一个字符,再次从头开始比较。
局限性
尽管朴素的字符串匹配算法易于理解和实现,但它在处理大型文本时效率较低。特别是当文本和子字符串较长,且匹配失败仅在子字符串的末尾时,朴素算法会进行大量的重复比较。这种低效率在数据量大或需要频繁执行匹配操作的应用中尤为突出。
字符串暴力搜索
字符串暴力搜索,又称朴素搜索算法,是一种基础且直观的字符串匹配方法。它尝试在一个主字符串(文本)中查找一个子字符串(模式),通过逐个字符比较来检查子字符串是否出现在主字符串中。让我们用一个简单的例子来说明暴力搜索的过程:
暴力搜索的步骤
假设我们有一个主字符串 S = "ABCDESD" 和一个要搜索的子字符串 P = "ES"。我们的目标是找到子字符串 P 在主字符串 S 中的位置(如果存在的话)。
初始化索引:我们从主字符串 S 的第一个字符开始,设主字符串的当前索引为 i = 0,子字符串的当前索引为 j = 0。
字符比较:比较 S[i] 和 P[j]:
- 如果
S[i] == P[j],我们将两个索引i和j同时增加1,继续比较下一个字符。 - 如果
S[i] != P[j],我们发现一个不匹配。此时,我们将子字符串P的索引j重置为0,并将主字符串S的索引i回溯到这次匹配尝试的起始位置的下一个字符(即i = i - j + 1)。
检查完整匹配:每次当 j 达到子字符串 P 的长度时,意味着我们找到了一个完整的匹配。记录下这个位置,然后像在不匹配的情况下一样,重置 j 为 0,并调整 i。
重复过程:重复以上步骤,直到主字符串 S 的末尾。
举个例子
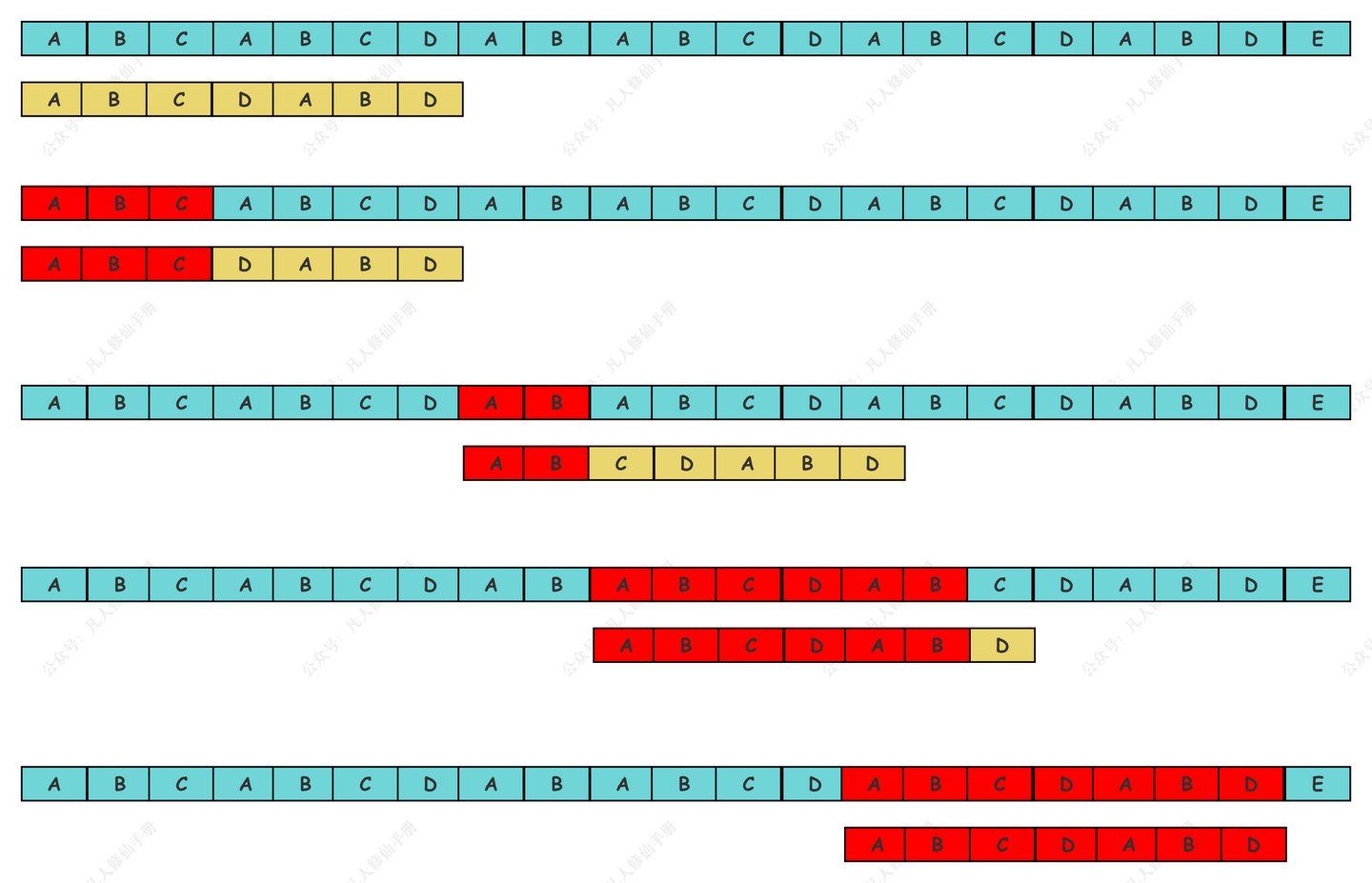
让我们通过一个简化的例子来具体说明暴力搜索的过程:
- 假设
S = "ABCABCDABABCDABCDABDE",P = "ABCDABD"。 - 开始时,
i = 0,j = 0,S[i]与P[j]匹配,继续向前比较。 - 当
i =3,j =3时,S[i]与P[j]不匹配。此时,我们将i回溯到1,j重置为0。 - 这个过程一直持续,直到我们找到完整的匹配或遍历完整个主字符串。
算法复杂度
暴力搜索算法的时间复杂度通常是 O(n*m),其中 n 是文本的长度,m 是模式的长度。在最坏的情况下,我们可能需要将模式与文本中的每个可能的位置进行比较。然而,在实际应用中,特别是当模式较短或在文本中较早出现时,暴力搜索的效率可能比理论上的最坏情况要好。
代码实现
1 | public static int bruteForce(String source, String pattern) { |
使用场景
尽管暴力搜索效率不高,但在一些特定场景下,例如短字符串的搜索或者数据量不大时,它仍然是一个可行的选择。此外,暴力搜索算法的实现简单,不需要预处理文本或模式,也不需要额外的存储空间,这使得它在某些资源受限的环境下仍然有其应用价值。
KMP 算法概述
KMP算法,由 Donald Knuth、Vaughan Pratt和James H. Morris 共同发明,是解决字符串匹配问题的一个经典算法。它的核心思想是,当在文本字符串中出现不匹配的情况时,可以利用已匹配的部分信息,避免从头开始匹配,从而提高搜索效率。
巧妙利用已匹配信息
KMP 算法的关键在于构建一个称为” 部分匹配表”(Partial Match Table)或” 失败函数” 的数据结构,这个表包含了关于子字符串自身重复模式的信息。在匹配过程中,当遇到不匹配的字符时,算法会参考这个表来决定下一步应该将子字符串向前移动多远,而不是简单地每次只移动一个字符。
高效性的来源
这种方法大大减少了不必要的比较次数,特别是在处理包含大量重复模式的字符串时更为显著。KMP 算法的时间复杂度是线性的,即 O(n+m),其中 n 是文本字符串的长度,m 是子字符串的长度。这使得 KMP 算法成为在实际应用中处理字符串匹配问题的一个高效选择。
KMP 算法核心原理
KMP 算法的高效之处在于它能够在不匹配发生时,通过预先计算得到的部分匹配表来决定下一步匹配应该开始的位置,从而避免了不必要的比较。这一节将详细解释构成 KMP 算法核心的几个关键概念:前缀、后缀和部分匹配表。
前缀和后缀
- 前缀:一个字符串的前缀是指从字符串的第一个字符开始的所有可能的子串。
- 后缀:一个字符串的后缀是指以字符串的最后一个字符结束的所有可能的子串。
在 KMP 算法中,通过比较子字符串的前缀和后缀,我们可以找到一些有用的模式,这些模式告诉我们在发生不匹配时如何有效地移动子字符串。
部分匹配表
部分匹配表(也称为” 失败函数”)是 KMP 算法中的核心数据结构。对于子字符串中的每个字符,部分匹配表记录了直到该字符为止的子字符串的前缀集合与后缀集合的最长公共元素的长度。这个长度告诉我们在不匹配发生时,子字符串应该向右移动多远。
构建部分匹配表
- 初始化:部分匹配表的第一个值总是 0,因为字符串的第一个字符没有前缀。
- 迭代计算:对于子字符串中的每个后续字符,我们查找最长的相同前缀和后缀。这个过程可以通过递归地使用已计算的部分匹配表值来高效完成。
1 | private static int[] computeLPSArray(String pattern) { |
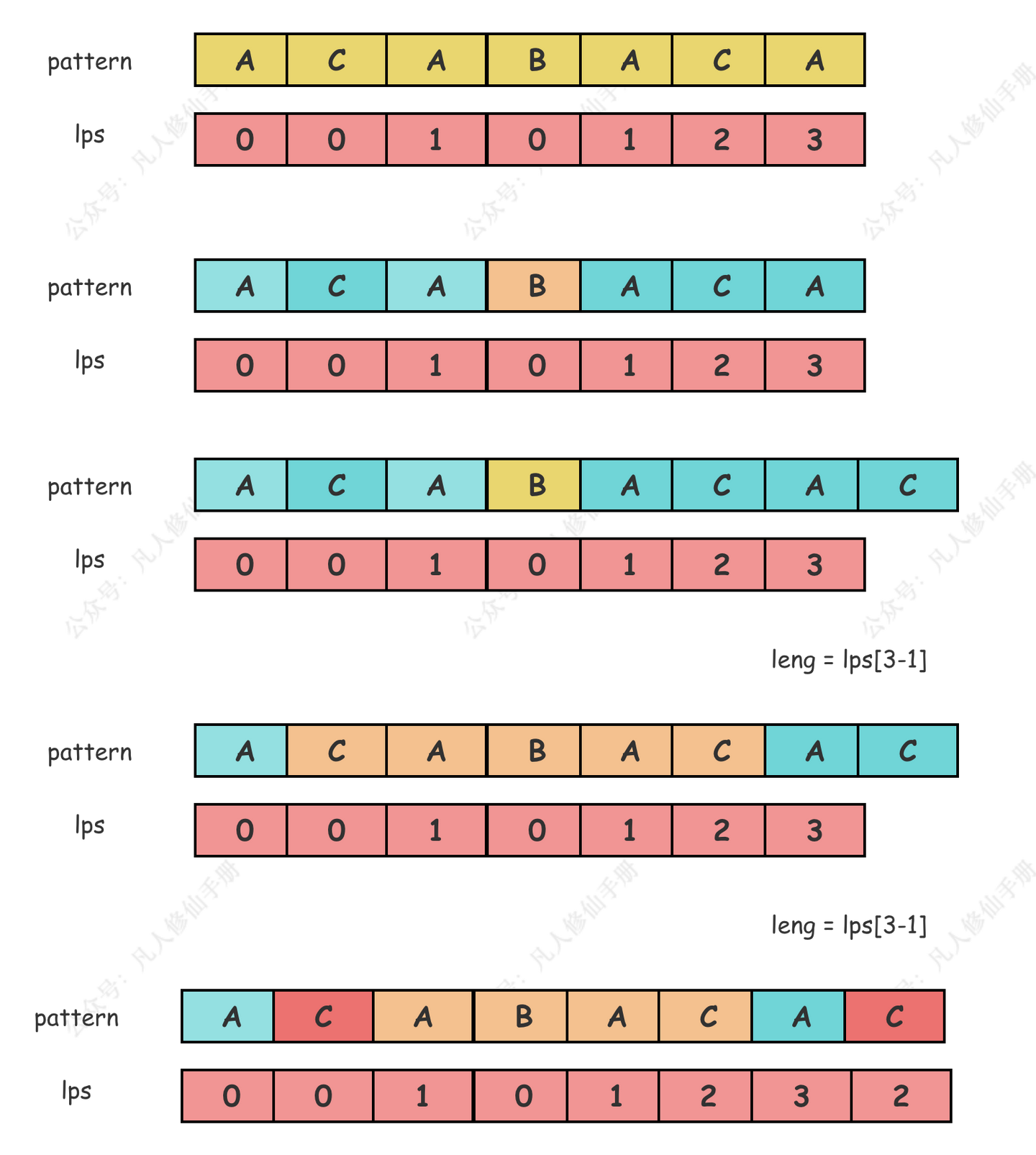
- 字符串
ACABACA的最长前缀后缀子串是 3 - 字符串增加
C后字符变成ACABACAC,此时重新计算字符串的lps值 - 由于字符 B 和字符 C 不相等,此时需要寻找更短的一个子串长度
leng=lps[leng-1] - 重复步骤 3,此时字符
C与新添加的字符C相等,寻找出一个更长子串,于是leng ++
利用部分匹配表进行匹配
当在文本字符串中进行匹配时,如果遇到不匹配的字符,我们可以查看部分匹配表来决定下一步的操作。表中的值告诉我们子字符串中有多大长度的字符已经是自匹配的,因此我们可以将子字符串向右移动这么多位,跳过这些已匹配的部分,直接从后续的字符开始比较。
Kmp 算法解决的问题
- 减少不必要的比较:在传统的暴力搜索算法中,每次模式字符串与主字符串中的某个子串不匹配时,搜索都会从主字符串的下一个字符重新开始,并重新检查模式字符串。这意味着许多比较实际上是在重复进行。KMP 算法通过预先分析模式字符串并构建一个部分匹配表(LPS 数组),在发生不匹配时,能够跳过那些已经知道不会匹配的部分,从而避免了这些不必要的比较。
- 提高搜索效率:通过使用部分匹配表,KMP 算法在遇到不匹配的情况时,可以将模式字符串向前滑动多于一位的距离,而不是仅仅滑动一位。这样,算法可以更快地跳过那些不可能匹配的部分,从而在整体上提高搜索的效率。
- 最坏情况下的性能保证:与暴力搜索算法相比,其性能严重依赖于模式字符串和主字符串的特定序列,在最坏的情况下可能需要进行 O (N*M) 次比较(N 是主字符串的长度,M 是模式字符串的长度),KMP 算法保证了在所有情况下的性能,最坏情况下的时间复杂度为 O (N),这使得 KMP 算法在处理长字符串和复杂模式匹配时尤为有效。
- 通用性和可靠性:KMP 算法不依赖于特定的字符集,它可以在任何类型的字符串数据上工作,包括二进制数据。因此,KMP 算法在各种应用中都非常可靠和通用,从文本处理到数据挖掘和生物信息学等领域。
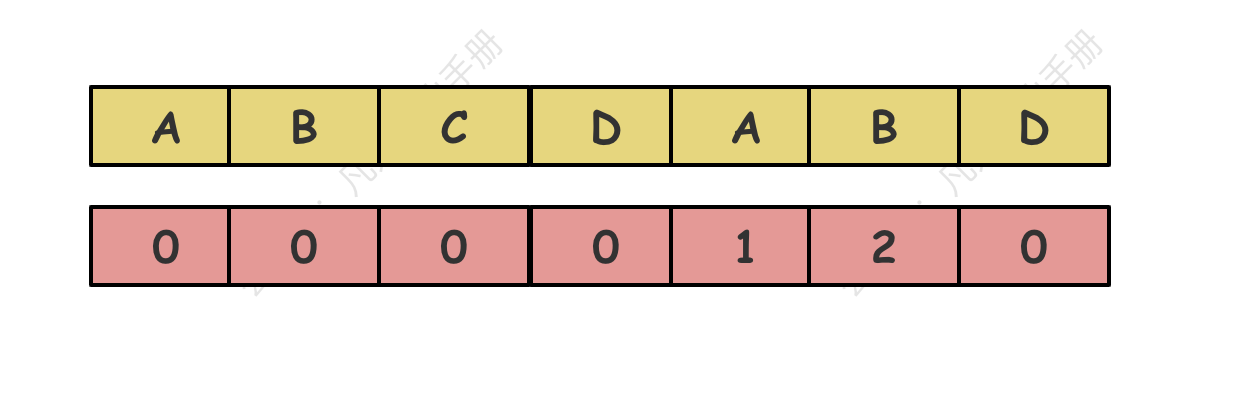
预处理模式字符串:
计算一个 LPS 数组,该数组表示在模式字符串中,每个子串的最长相同前缀和后缀的长度。这个信息用于在发生不匹配时,决定如何移动模式字符串以利用之前的匹配信息,而不是从头开始。

在暴力搜索情况下,当出现不匹配时,只能移动一位,然后再次比较,如图 4:

在 KMP 算法中,当出现不匹配时,j=lps [j-1] ,如图 5
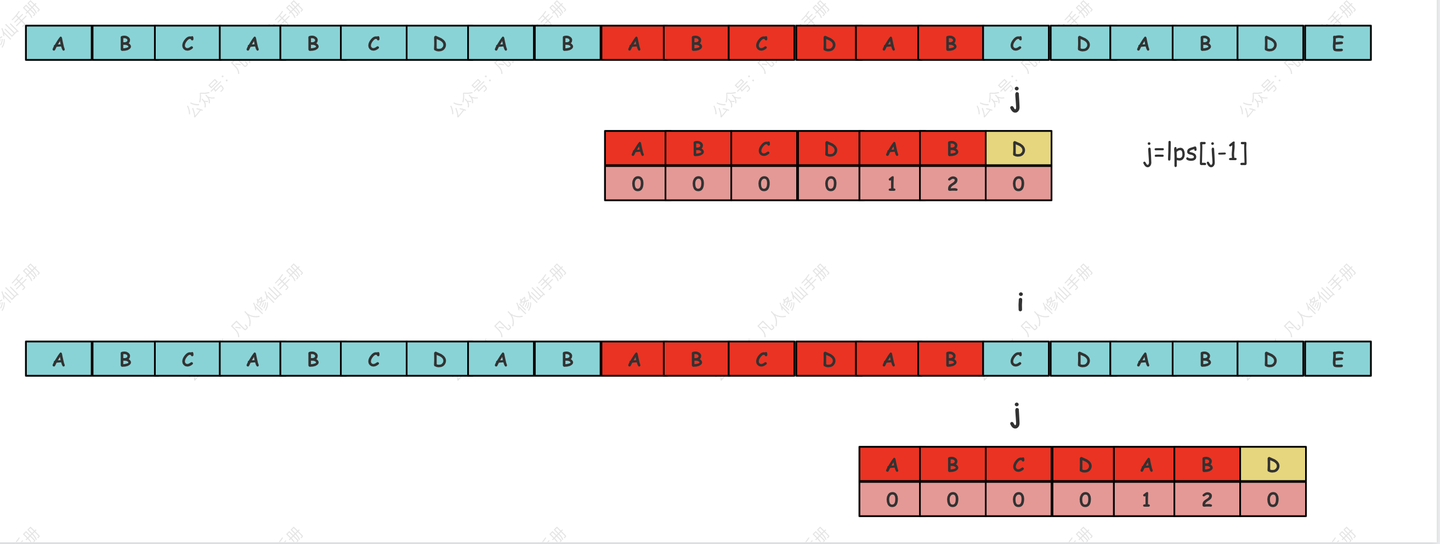
搜索过程:
使用 LPS 数组执行搜索。当在主字符串中遇到不匹配时,LPS 数组指示模式字符串下一步应该移动的位置,从而跳过了已经知道不会匹配的部分。
Java 实现
1 | public static void kmpSearch(String text, String pattern) { |
代码解析
- KMPSearch 方法是搜索算法的主体,它接受模式字符串 pat 和主字符串 txt 作为输入,并输出模式字符串在主字符串中出现的所有位置。
- computeLPSArray 方法用于计算给定模式字符串的 LPS 数组。LPS 数组对于每个子串 pat [0…i] 保存了在 pat [0…i] 中的最长相等前缀和后缀的长度。
- 在 KMPSearch 中,通过比较 txt 和 pat 来进行搜索,当遇到不匹配时,使用 lps 数组来决定下一步的搜索位置,这样可以避免从模式字符串的起始位置重新开始搜索,从而提高搜索效率。
时间复杂度
KMP 算法的时间复杂度为 O (N),其中 N 是主字符串的长度,这比朴素的字符串搜索算法,时间复杂度为 O (NM),M 是模式字符串的长度要高效得多。